


Liquid AI just released LFM2.5-VL-450M, an updated version of its earlier LFM2-VL-450M vision-language model. The new release introduces bounding box prediction, improved instruction following, expanded multilingual understanding, and function calling support — all within a 450M-parameter footprint designed to run directly on edge hardware ranging from embedded AI modules like NVIDIA Jetson Orin, to mini-PC APUs like AMD Ryzen AI Max+ 395, to flagship phone SoCs like the Snapdragon 8 Elite inside the Samsung S25 Ultra.
What is a Vision-Language Model and Why Model Size Matters
Before going deeper, it helps to understand what a vision-language model (VLM) is. A VLM is a model that can process both images and text together — you can send it a photo and ask questions about it in natural language, and it will respond. Most large VLMs require substantial GPU memory and cloud infrastructure to run. That’s a problem for real-world deployment scenarios like warehouse robots, smart glasses, or retail shelf cameras, where compute is limited and latency must be low.
LFM2.5-VL-450M is Liquid AI’s answer to this constraint: a model small enough to fit on edge hardware while still supporting a meaningful set of vision and language capabilities.
Architecture and Training
LFM2.5-VL-450M uses LFM2.5-350M as its language model backbone and SigLIP2 NaFlex shape-optimized 86M as its vision encoder. The context window is 32,768 tokens with a vocabulary size of 65,536.
For image handling, the model supports native resolution processing up to 512×512 pixels without upscaling, preserves non-standard aspect ratios without distortion, and uses a tiling strategy that splits large images into non-overlapping 512×512 patches while including thumbnail encoding for global context. The thumbnail encoding is important: without it, tiling would give the model only local patches with no sense of the overall scene. At inference time, users can tune the maximum image tokens and tile count for a speed/quality tradeoff without retraining, which is useful when deploying across hardware with different compute budgets.
The recommended generation parameters from Liquid AI are temperature=0.1, min_p=0.15, and repetition_penalty=1.05 for text, and min_image_tokens=32, max_image_tokens=256, and do_image_splitting=True for vision inputs.
On the training side, Liquid AI scaled pre-training from 10T to 28T tokens compared to LFM2-VL-450M, followed by post-training using preference optimization and reinforcement learning to improve grounding, instruction following, and overall reliability across vision-language tasks.
New Capabilities Over LFM2-VL-450M
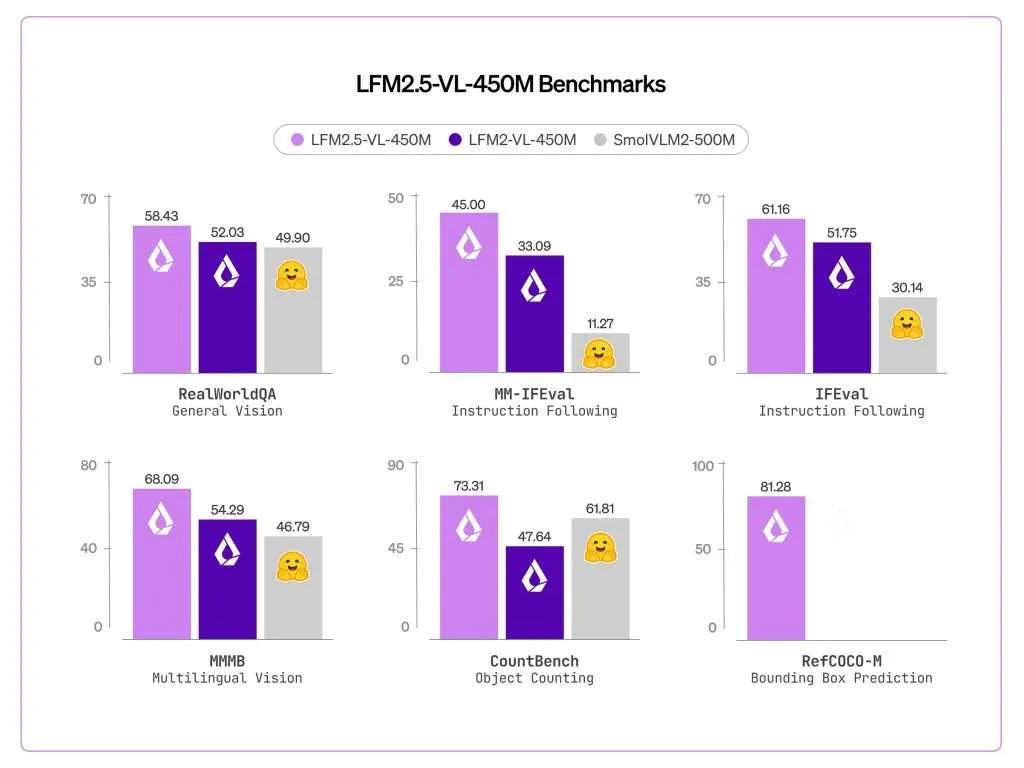
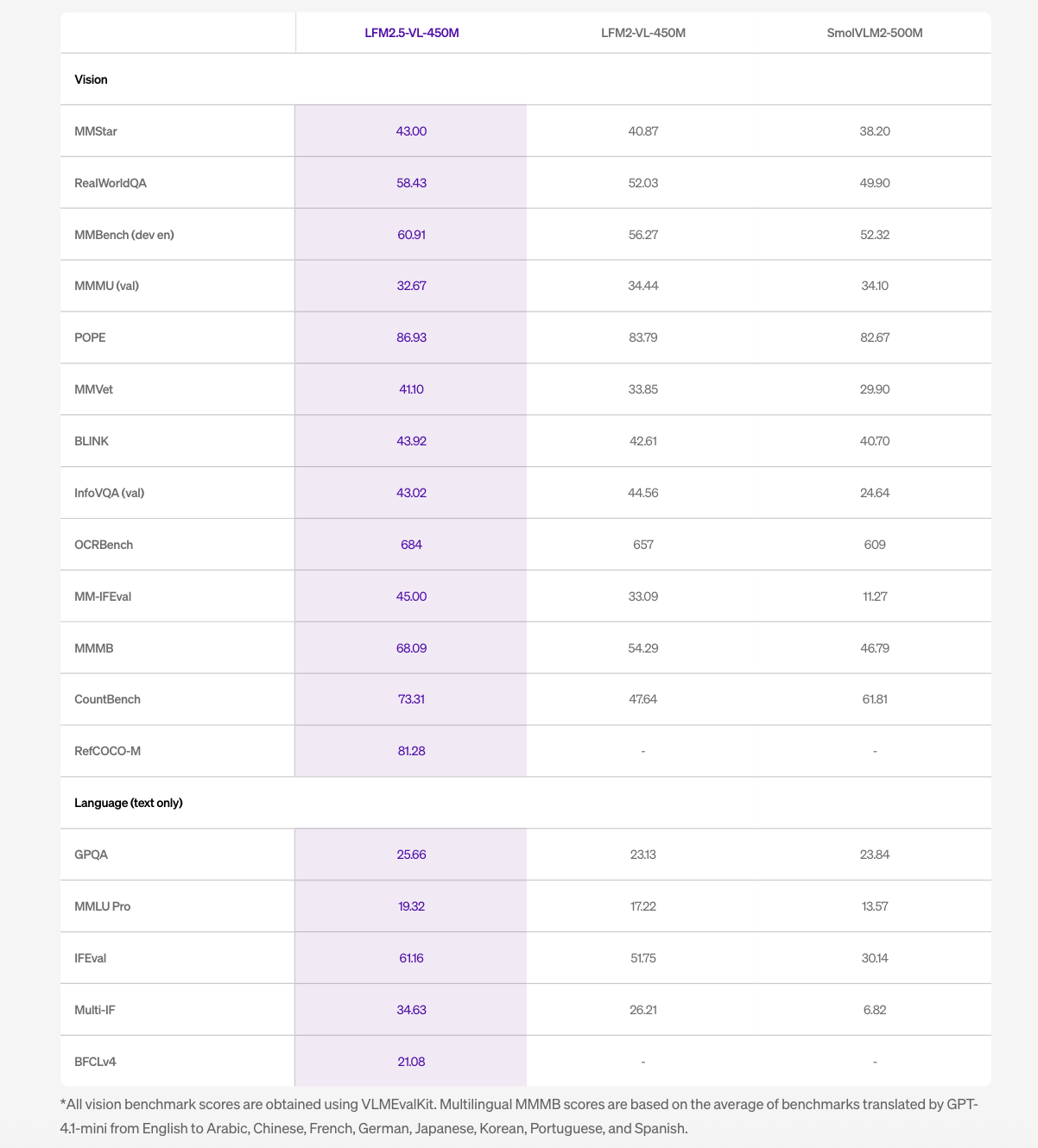
The most significant addition is bounding box prediction. LFM2.5-VL-450M scored 81.28 on RefCOCO-M, up from zero on the previous model. RefCOCO-M is a visual grounding benchmark that measures how accurately a model can locate an object in an image given a natural language description. In practice, the model outputs structured JSON with normalized coordinates identifying where objects are in a scene — not just describing what is there, but also locating it. This is meaningfully different from pure image captioning and makes the model directly usable in pipelines that need spatial outputs.
Multilingual support also improved substantially. MMMB scores improved from 54.29 to 68.09, covering Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish. This is relevant for global deployments where local-language prompts must be understood alongside visual inputs, without needing separate localization pipelines.
Instruction following improved as well. MM-IFEval scores went from 32.93 to 45.00, meaning the model more reliably adheres to explicit constraints given in a prompt — for example, responding in a particular format or restricting output to specific fields.
Function calling support for text-only input was also added, measured by BFCLv4 at 21.08, a capability the previous model did not include. Function calling allows the model to be used in agentic pipelines where it needs to invoke external tools — for instance, calling a weather API or triggering an action in a downstream system.
Benchmark Performance
Across vision benchmarks evaluated using VLMEvalKit, LFM2.5-VL-450M outperforms both LFM2-VL-450M and SmolVLM2-500M on most tasks. Notable scores include 86.93 on POPE, 684 on OCRBench, 60.91 on MMBench (dev en), and 58.43 on RealWorldQA.
Two benchmark gains stand out beyond the headline numbers. MMVet — which tests more open-ended visual understanding — improved from 33.85 to 41.10, a substantial relative gain. CountBench, which evaluates the model’s ability to count objects in a scene, improved from 47.64 to 73.31, one of the largest relative improvements in the table. InfoVQA held roughly flat at 43.02 versus 44.56 on the prior model.
On language-only benchmarks, IFEval improved from 51.75 to 61.16 and Multi-IF from 26.21 to 34.63. The model does not outperform on all tasks — MMMU (val) dropped slightly from 34.44 to 32.67 — and Liquid AI notes the model is not well-suited for knowledge-intensive tasks or fine-grained OCR.
Edge Inference Performance
LFM2.5-VL-450M with Q4_0 quantization runs across the full range of target hardware, from embedded AI modules like Jetson Orin to mini-PC APUs like Ryzen AI Max+ 395 to flagship phone SoCs like Snapdragon 8 Elite.
The latency numbers tell a clear story. On Jetson Orin, the model processes a 256×256 image in 233ms and a 512×512 image in 242ms — staying well under 250ms at both resolutions. This makes it fast enough to process every frame in a 4 FPS video stream with full vision-language understanding, not just detection. On Samsung S25 Ultra, latency is 950ms for 256×256 and 2.4 seconds for 512×512. On AMD Ryzen AI Max+ 395, it is 637ms for 256×256 and 944ms for 512×512 — under one second for the smaller resolution on both consumer devices, which keeps interactive applications responsive.
Real-World Use Cases
LFM2.5-VL-450M is especially well suited to real-world deployments where low latency, compact structured outputs, and efficient semantic reasoning matter most, including settings where offline operation or on-device processing is important for privacy.
In industrial automation, compute-constrained environments such as passenger vehicles, agricultural machinery, and warehouses often limit perception models to bounding-box outputs. LFM2.5-VL-450M goes further, providing grounded scene understanding in a single pass — enabling richer outputs for settings like warehouse aisles, including worker actions, forklift movement, and inventory flow — while still fitting existing edge hardware like a Jetson Orin.
For wearables and always-on monitoring, devices such as smart glasses, body-worn assistants, dashcams, and security or industrial monitors cannot afford large perception stacks or constant cloud streaming. An efficient VLM can produce compact semantic outputs locally, turning raw video into useful structured understanding while keeping compute demands low and preserving privacy.
In retail and e-commerce, tasks like catalog ingestion, visual search, product matching, and shelf compliance require more than object detection, but richer visual understanding is often too expensive to deploy at scale. LFM2.5-VL-450M makes structured visual reasoning practical for these workloads.
Key Takeaways
- LFM2.5-VL-450M adds bounding box prediction for the first time, scoring 81.28 on RefCOCO-M versus zero on the previous model, enabling the model to output structured spatial coordinates for detected objects — not just describe what it sees.
- Pre-training was scaled from 10T to 28T tokens, combined with post-training via preference optimization and reinforcement learning, driving consistent benchmark gains across vision and language tasks over LFM2-VL-450M.
- The model runs on edge hardware with sub-250ms latency, processing a 512×512 image in 242ms on NVIDIA Jetson Orin with Q4_0 quantization — fast enough for full vision-language understanding on every frame of a 4 FPS video stream without cloud offloading.
- Multilingual visual understanding improved significantly, with MMMB scores rising from 54.29 to 68.09 across Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish, making the model viable for global deployments without separate localization models.
Check out the Technical details and Model Weight. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
