Speech technology still has a data distribution problem. Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) systems have improved rapidly for high-resource languages, but many African languages remain poorly represented in open corpora. A team of researchers from Google and other collaborators introduce WAXAL, an open multilingual speech dataset for African languages covering 24 languages, with an ASR component built from transcribed natural speech and a TTS component built from studio-quality single-speaker recordings.
WAXAL is structured as two separate resources because ASR and TTS have different data requirements. The ASR side is designed around diverse speakers, natural environments, and spontaneous language production. The TTS side is designed around controlled recording conditions, phonetically balanced scripts, and cleaner single-speaker audio suited for synthesis. That separation is technically important: a dataset that is useful for robust recognition in noisy real-world settings is usually not the same dataset that produces strong single-speaker TTS models.
How the ASR data was collected
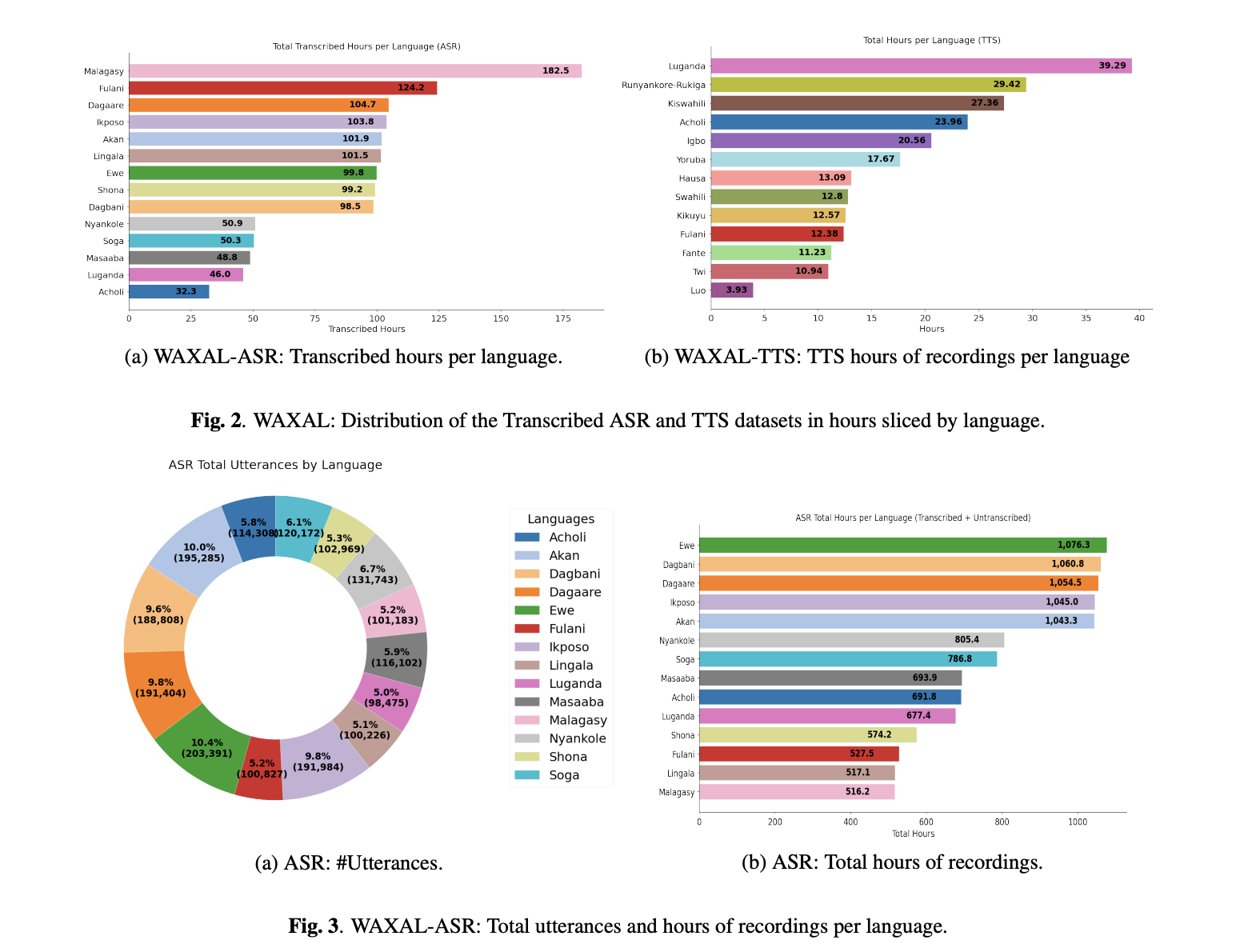
The ASR portion of WAXAL was collected using image-prompted speech. Speakers were shown images and asked to describe what they saw in their native language, which is a more natural setup than simple prompted reading. Recordings were captured in speakers’ natural environments, each with a minimum duration of 15 seconds. The collection process also tracked metadata such as speaker age, gender, language, and recording environment. Only a subset of the full collected audio was transcribed: the research team states that the current ASR release includes transcriptions for about 10% of the total recorded audio. Those transcriptions were produced by paid local linguistic experts, using local scripts where available and English-alphabet transliteration otherwise.
This is important for anyone building multilingual ASR systems. Image-prompted speech tends to capture more natural lexical and syntactic variation than tightly scripted reading, but it also makes transcription harder and increases variation across speakers, domains, and acoustic conditions. WAXAL leans into that tradeoff rather than avoiding it. The result is not a perfectly clean benchmark dataset; it is closer to a field-collected multilingual ASR data with real variability baked in.

How the TTS data was collected
The TTS side of WAXAL was built very differently. The TTS dataset was designed for high-quality, single-speaker synthetic voices. For each target language, the research team created a phonetically balanced script of approximately 108,500 words. They contracted 72 community participants, evenly split between male and female voice actors, and recorded them in professional studio-like environments to reduce background noise and preserve audio fidelity. The target was approximately 16 hours of clean edited audio per voice actor.
This is the right design choice for synthesis. TTS models care much more about consistency in pronunciation, recording conditions, microphone quality, and speaker identity than ASR systems do. WAXAL therefore avoids the common mistake of treating ‘speech data’ as a single category, when in practice ASR and TTS pipelines want very different supervision signals.
Key Takeaways
- WAXAL is an open multilingual speech corpus built for low-resource African language ASR and TTS.
- The ASR data uses image-prompted, natural speech collected in real-world environments.
- The TTS data uses studio-quality, single-speaker recordings with phonetically balanced scripts.
Check out Paper and Dataset here. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.