

Everyone talks about LLMs—but today’s AI ecosystem is far bigger than just language models. Behind the scenes, a whole family of specialized architectures is quietly transforming how machines see, plan, act, segment, represent concepts, and even run efficiently on small devices. Each of these models solves a different part of the intelligence puzzle, and together they’re shaping the next generation of AI systems.
In this article, we’ll explore the five major players: Large Language Models (LLMs), Vision-Language Models (VLMs), Mixture of Experts (MoE), Large Action Models (LAMs) & Small Language Models (SLMs).
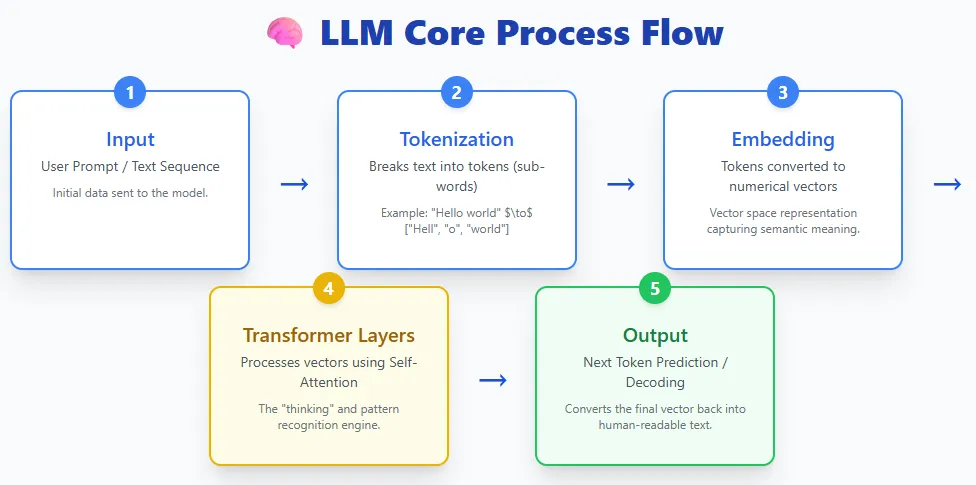
LLMs take in text, break it into tokens, turn those tokens into embeddings, pass them through layers of transformers, and generate text back out. Models like ChatGPT, Claude, Gemini, Llama, and others all follow this basic process.
At their core, LLMs are deep learning models trained on massive amounts of text data. This training allows them to understand language, generate responses, summarize information, write code, answer questions, and perform a wide range of tasks. They use the transformer architecture, which is extremely good at handling long sequences and capturing complex patterns in language.

Today, LLMs are widely accessible through consumer tools and assistants—from OpenAI’s ChatGPT and Anthropic’s Claude to Meta’s Llama models, Microsoft Copilot, and Google’s Gemini and BERT/PaLM family. They’ve become the foundation of modern AI applications because of their versatility and ease of use.
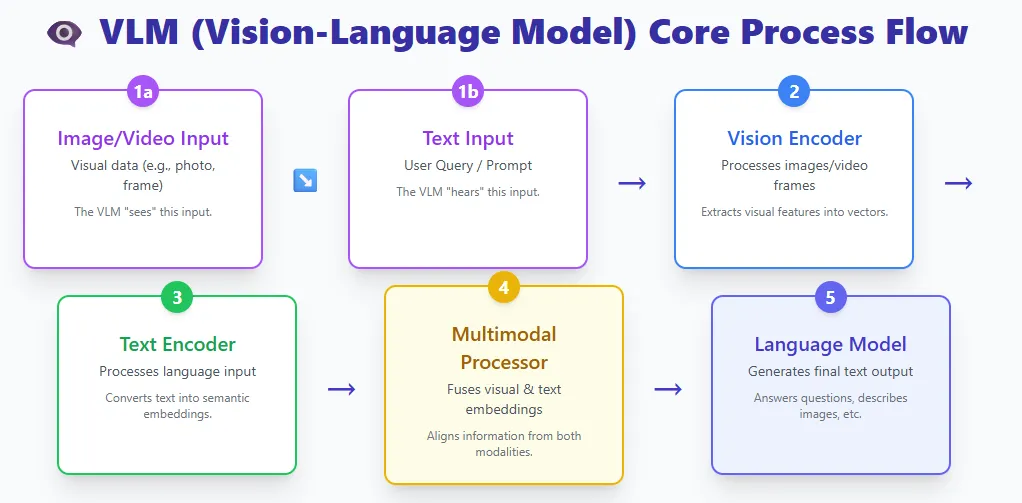
VLMs combine two worlds:
- A vision encoder that processes images or video
- A text encoder that processes language
Both streams meet in a multimodal processor, and a language model generates the final output.
Examples include GPT-4V, Gemini Pro Vision, and LLaVA.
A VLM is essentially a large language model that has been given the ability to see. By fusing visual and text representations, these models can understand images, interpret documents, answer questions about pictures, describe videos, and more.
Traditional computer vision models are trained for one narrow task—like classifying cats vs. dogs or extracting text from an image—and they can’t generalize beyond their training classes. If you need a new class or task, you must retrain them from scratch.
VLMs remove this limitation. Trained on huge datasets of images, videos, and text, they can perform many vision tasks zero-shot, simply by following natural language instructions. They can do everything from image captioning and OCR to visual reasoning and multi-step document understanding—all without task-specific retraining.
This flexibility makes VLMs one of the most powerful advances in modern AI.
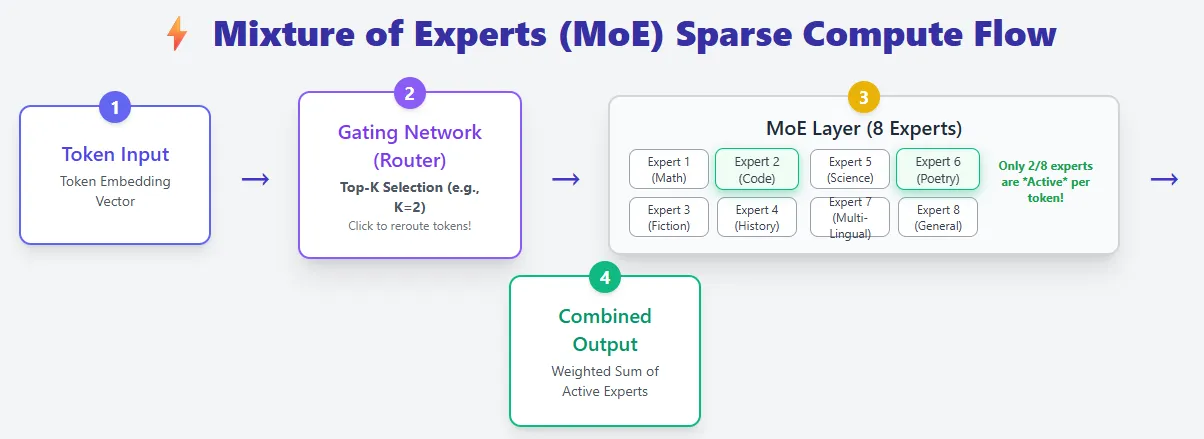
Mixture of Experts models build on the standard transformer architecture but introduce a key upgrade: instead of one feed-forward network per layer, they use many smaller expert networks and activate only a few for each token. This makes MoE models extremely efficient while offering massive capacity.
In a regular transformer, every token flows through the same feed-forward network, meaning all parameters are used for every token. MoE layers replace this with a pool of experts, and a router decides which experts should process each token (Top-K selection). As a result, MoE models may have far more total parameters, but they only compute with a small fraction of them at a time—giving sparse compute.
For example, Mixtral 8×7B has 46B+ parameters, yet each token uses only about 13B.
This design drastically reduces inference cost. Instead of scaling by making the model deeper or wider (which increases FLOPs), MoE models scale by adding more experts, boosting capacity without raising per-token compute. This is why MoEs are often described as having “bigger brains at lower runtime cost.”
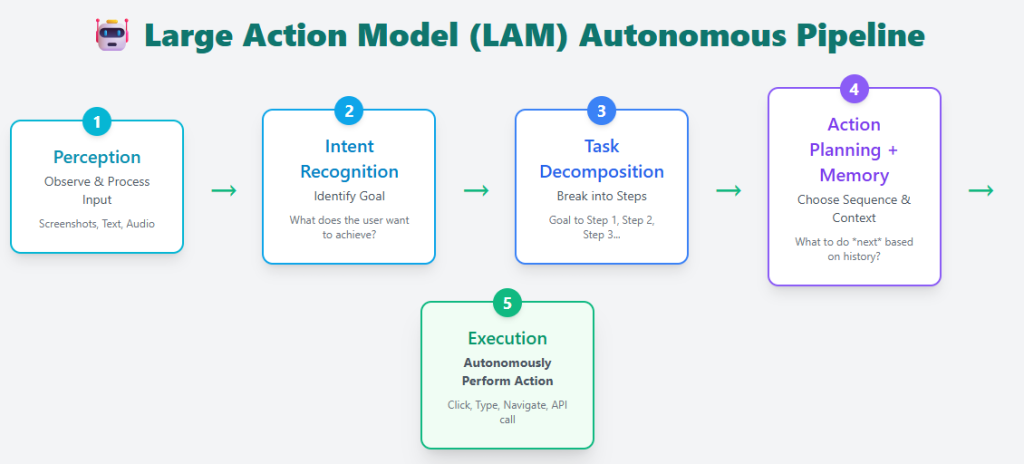
Large Action Models go a step beyond generating text—they turn intent into action. Instead of just answering questions, a LAM can understand what a user wants, break the task into steps, plan the required actions, and then execute them in the real world or on a computer.
A typical LAM pipeline includes:
- Perception – Understanding the user’s input
- Intent recognition – Identifying what the user is trying to achieve
- Task decomposition – Breaking the goal into actionable steps
- Action planning + memory – Choosing the right sequence of actions using past and present context
- Execution – Carrying out tasks autonomously
Examples include Rabbit R1, Microsoft’s UFO framework, and Claude Computer Use, all of which can operate apps, navigate interfaces, or complete tasks on behalf of a user.
LAMs are trained on massive datasets of real user actions, giving them the ability to not just respond, but act—booking rooms, filling forms, organizing files, or performing multi-step workflows. This shifts AI from a passive assistant into an active agent capable of complex, real-time decision-making.
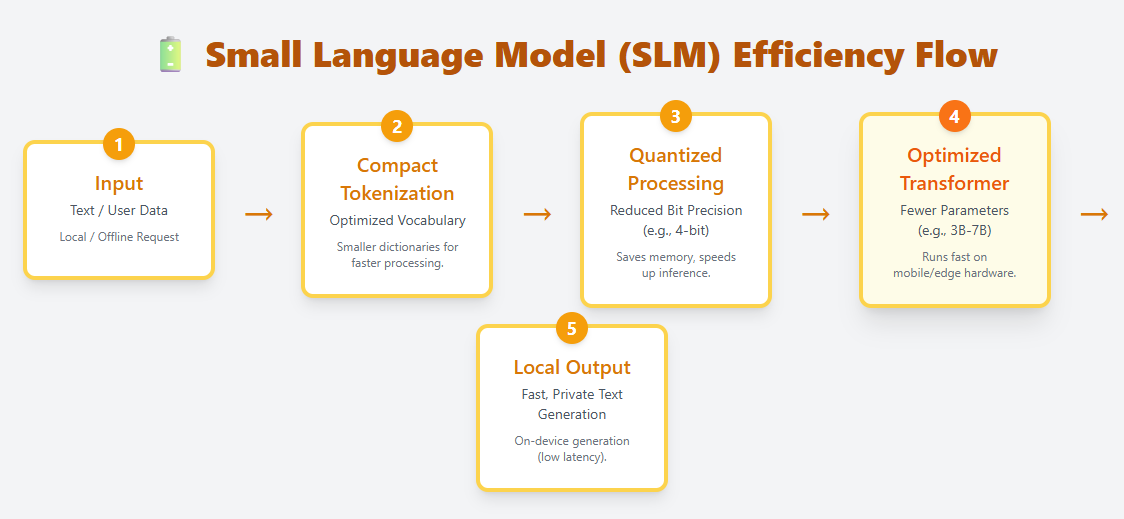
SLMs are lightweight language models designed to run efficiently on edge devices, mobile hardware, and other resource-constrained environments. They use compact tokenization, optimized transformer layers, and aggressive quantization to make local, on-device deployment possible. Examples include Phi-3, Gemma, Mistral 7B, and Llama 3.2 1B.
Unlike LLMs, which may have hundreds of billions of parameters, SLMs typically range from a few million to a few billion. Despite their smaller size, they can still understand and generate natural language, making them useful for chat, summarization, translation, and task automation—without needing cloud computation.
Because they require far less memory and compute, SLMs are ideal for:
- Mobile apps
- IoT and edge devices
- Offline or privacy-sensitive scenarios
- Low-latency applications where cloud calls are too slow
SLMs represent a growing shift toward fast, private, and cost-efficient AI, bringing language intelligence directly onto personal devices.

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.

